Show Your Work
On discovering that “show your work” is not the same thing as “do the work well.”
When I first started using Claude Code last summer, it felt like a chatty junior engineer who couldn’t wait to tell you what it was thinking. It kept you in the loop. It explained itself. It told you what it was about to try, why it thought that might work, and then narrated its way through whether it did. There was charm in it. You felt like you were pairing.
Now Claude Code sits there like a Zen Buddhist monk, slowly mulling the problem in silence, and then suddenly exclaims “TADA!” and hands you a diff. This is not the chatty pair I remember. All the in-depth thinking, the running commentary, the visible reasoning that gave it such charm has quietly disappeared, and what’s left is this churning quiet system that is all work and no play.
So I have been leaning more and more on opencode. It talks. It thinks in a personable way. It structures its thoughts so I can follow along. And more importantly, it doesn’t hide its working. It felt like maths in school: show your work. Opencode shows its work. Claude Code doesn’t. And it has been astonishing to me how much I valued being able to read the thinking along the way.
That is where this post would have ended a few weeks ago. A grumpy aside about how Claude Code lost its voice. Opencode won, etc, etc. Move on.
Except the question wormed its way in. Am I right? I have a strong opinion about which harness you should use, and the opinion is built almost entirely on vibes. On who I enjoy talking to. On whether the chat feels good. None of that tells me anything about which harness actually produces better code. And once that question is in your head it doesn’t leave.
I thought I was building a small harness comparison. In hindsight I was building something stranger: a tiny automated judgement machine for code, of the sort I had been hearing people gesture at without quite understanding what they meant.
A small experiment
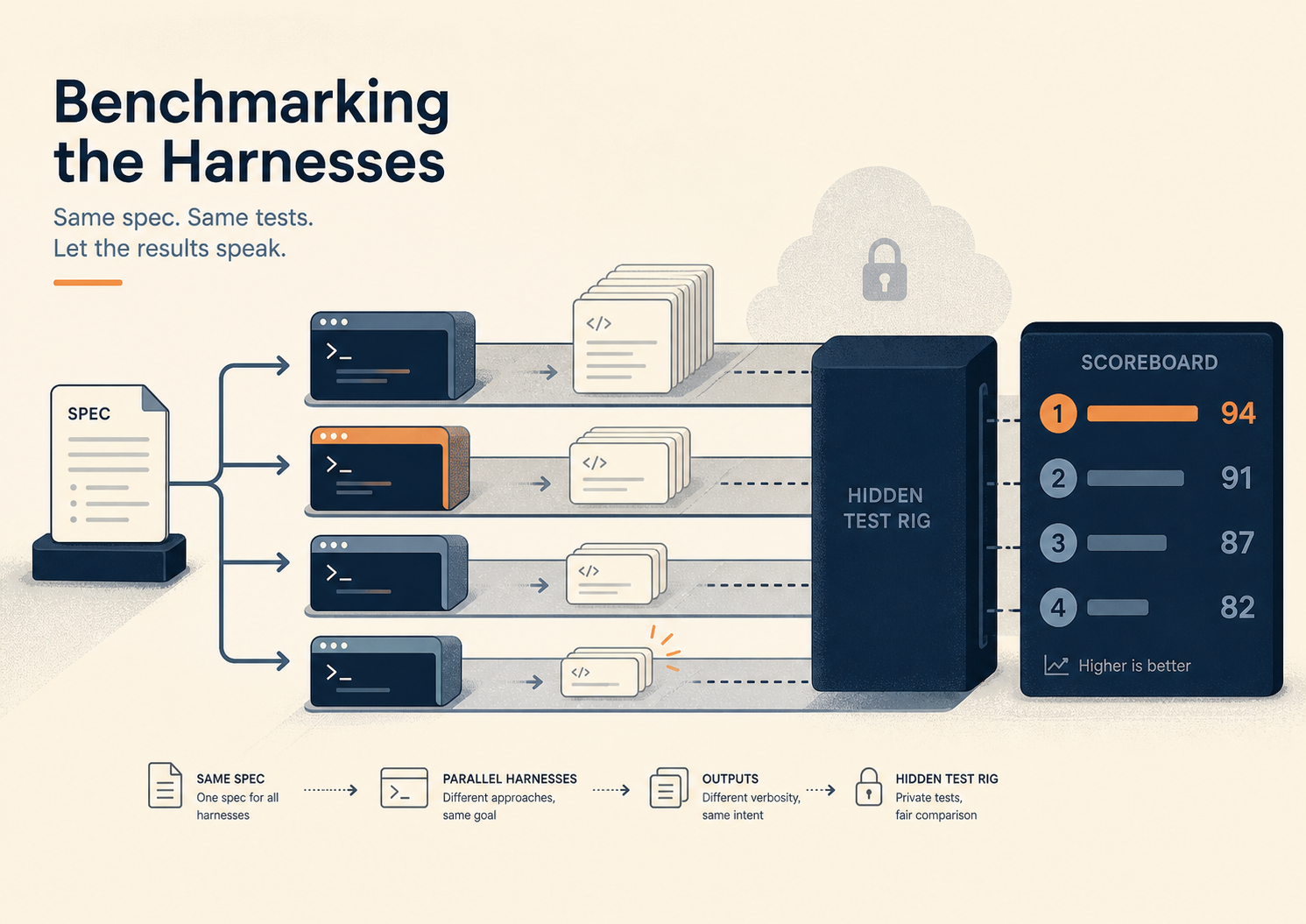
So I tried to be a bit Baconian about it. Same prompt, same starting state, run it through every harness and model combination I could get my hands on, multiple times, and grade the output against tests the agent never gets to see.
The setup was a fake Library API. A small but not trivial OpenAPI spec covering books, loans, fines, and members. Cursor pagination. Polymorphic loan responses where active loans look different from returned ones. An async payment polling flow with a terminal state. Structured API errors that should be preserved through the client. The agent’s job was to build a typed TypeScript client. No code generation, no runtime dependencies, just read the spec and write the thing.
The catch was a hidden test suite. The agent could write its own tests, run its own validation, do whatever it wanted to convince itself the implementation worked. But the grading happened against a separate Vitest suite the agent never saw. That suite poked at all the bits I expected harnesses to get wrong: did the cursor pagination actually iterate, did the async payment poll reach a terminal state, did the polymorphic loan response preserve both shapes, did API errors surface usefully or get flattened into “Error: request failed”. The agent could not optimise to it because it could not see it.
Six combinations. Five runs each. Thirty implementations of a Library API client. The rig is on GitHub if you want to poke at it.
I did not go into this neutrally. I had a favourite. I expected opencode-opus to win, claude-code to look quietly competent but a bit lifeless, and the GPT-backed runs to come in mid-pack. I thought I knew the shape of the answer before I started.
While I was setting it up, something else started to nag at me. I had been hearing the term “dark factory” floating around in the agentic coding conversation and not really understanding what people meant. A factory that runs without lights because there are no humans in it. Applied to coding, it suggested some end state where you specify what you want, an agent produces it, and something else judges whether it is correct, all without you in the loop. I had nodded along when people brought it up and quietly had no idea how you would actually build one. But the rig I was assembling was starting to look uncomfortably like a small piece of that picture, and I tried not to think about it too hard while I was still building the thing.
The results
I will spare you the full grid. Each run was scored out of 20 hidden tests, and each harness/model pair ran five times, so the maximum score per row is 100. The headline numbers:
| Harness | Hidden tests | Perfect runs | Median diff |
|---|---|---|---|
| claude-code | 98/100 | 4/5 | 1157 |
| opencode-opus | 97/100 | 3/5 | 628 |
| pi-gpt | 92/100 | 1/5 | 1444 |
| pi-opus | 90/100 | 1/5 | 1401 |
| codex | 85/100 | 2/5 | 863 |
| opencode-gpt | 85/100 | 2/5 | 732 |
Median diff is measured in lines changed per run.
Claude Code won on correctness. Four perfect runs out of five. The harness I had been quietly resenting for going silent on me produced the most reliable code in the experiment. I sat with that for a bit. The chatty junior I missed had grown up into the engineer who just gets it done and hands you the result, and apparently the result is good.
Opencode-opus came in essentially tied on correctness, one point behind. But look at the median diff. 628 lines vs 1157. Same task, same spec, near identical scores, and opencode-opus did it in a little over half the code. If you measure tests passed per hundred lines of diff, opencode-opus is comfortably the best of the lot at around three. Claude Code is a touch under two. Pi-opus is at one and change. It is a crude metric, obviously. Fewer lines are not inherently better, and there are plenty of ways to cheat at it. But when two runs are almost tied on correctness and one gets there with half the diff, I pay attention. Claude Code is most reliable. Opencode-opus is most efficient. I am genuinely not sure which I value more in a real engineering context.
The other observation that I keep turning over is the pi.dev runs. Largest diffs in the experiment, mid-pack on correctness. More generated code did not buy reliability. It is tempting to read a wall of plausible-looking output as evidence of diligence. The data here says that intuition is wrong. Verbose was not safer. Verbose was just verbose.
A caveat there, though, and an important one. The pi.dev runs were stock pi out of the box. No customisation, no extra tools, no extension of its capabilities. And the whole point of pi is that you customise it. That is the entire pitch. So what I actually measured was vanilla pi, with a deliberately limited toolkit, on a task that probably wanted a richer one. Seen that way, the fact that pi-gpt landed at 92 with no help from me is genuinely interesting. There is more to do here, and a properly outfitted pi might tell a different story. That is its own post.
The same-model-different-harness comparison is where it gets weirder. Codex and opencode-gpt are both GPT-5.5 doing the same task, and they tied on aggregate score, but opencode-gpt did it in noticeably less code. Same brain, different harness, different shape of output. Then flip it: opencode-gpt vs opencode-opus is the same harness with different models, and the model swap moved the score from 85 to 97. So harness matters. Model matters. They are not interchangeable variables, and which one matters more depends on which one you change.
What this rig had become
Once the runs were done and I was staring at the spreadsheet, the thing I had been trying not to think about earlier became impossible to ignore.
I had a detailed work order in prompt.md and AGENTS.md and a formal OpenAPI spec. I had a clean starting workspace that got reset between runs. I had a constrained implementation environment with locked Node and TypeScript versions. I had a hidden acceptance test suite the agent could not see or game. I had a mock service that behaved enough like a real one to be tested against. I had a runner that could launch any of the harnesses under comparable conditions, and a grader that built the output, ran the hidden tests, captured the diff size, and recorded the results into a table.
That is most of a dark factory. Spec in, code out, automated judgement in the middle, results captured for analysis, no human required during a run. The piece that is missing is the feedback loop. Right now, when a run scores 15 out of 20, that is the end of the story. It gets logged and we move on. A dark factory v0.1 would read those failures, decide whether to retry, mutate the prompt or the constraints, launch another attempt, and keep going until the score crossed some threshold or the budget ran out.
I do not have that yet. But I can see how to build it from here, which is something I genuinely could not see a month ago. I had been hearing the term and nodding politely. Now I had accidentally built most of one because I was trying to settle a vibes-based argument with myself about which harness I liked best.
And the thing that makes me uncomfortable about that is what it implies about “show your work”. I had been treating the visible reasoning as a proxy for trust. Watching opencode talk through the problem made me feel like it knew what it was doing. Watching Claude Code go quiet made me feel like it didn’t. The hidden tests did not care about either of those feelings. They cared about whether the cursor pagination iterated, whether the polymorphic loan response preserved both shapes, whether the async payment poll reached a terminal state. Visible reasoning helped me supervise. Hidden tests measured whether the work was actually done. Those turn out not to be the same thing, and inside a dark factory only one of them survives, because there is no human there to be reassured by the other.
What I am left with
I expected this experiment to vindicate opencode. It did not. If I cared only about pass rate I would use Claude Code. If I cared about correctness density I would use opencode-opus. If I cared about reading the agent’s reasoning while it works, I would still use opencode, and I will. Aesthetics matter. I spend hours in this tool. I want to enjoy being there.
But I am going to stop pretending that preference is a quality argument. It is a supervision argument, which is a different thing, and one that gets thinner the further you move toward letting the rig run on its own.
The other thing I am left with is the rig itself. I started building it to answer a small question and ended up with a thing that has the shape of something much bigger. That is the part I did not see coming. The benchmark was supposed to be the point. It turns out the benchmark might just be the prototype.